Stop Treating YAML Like a String
A new approach to Kubernetes configuration management
Koreo is a data structure orchestration engine. Although it’s primarily designed for Kubernetes resource orchestration, Koreo’s core functionality can orchestrate and manage virtually any structured data. What Koreo provides today, however, is a new approach to Kubernetes configuration management empowering developers and platform teams through programmable workflows. This approach draws upon the strengths of existing tools like Helm, Kustomize, and Crossplane while addressing some of their limitations. A foundational part of this lies in how Koreo handles configuration itself, specifically the distinction between “interpolation vs. overlay”.
String-interpolated templates
String-interpolation-based templating like Helm has its roots in the rudimentary templating approaches of early web technologies such as CGI, PHP, and ASP.NET. This pattern persists in many popular templating solutions (like Jinja and Go templates) because HTML’s complex structure makes it notoriously difficult to parse and manipulate programmatically. While some solutions, such as Elm UI or JSX-based approaches, offer cleaner, more structured HTML generation, most languages lack robust built-in mechanisms for this. And, no language lets you actually manipulate HTML with any confidence or precision. HTML is so painful that it is easier to treat as a string and, thus, we have string-interpolation-based templates.
Really, this is fine for many text-encoded data structures. Visually, when you’ve got one value to set within a data structure like YAML, it’s clear that it makes sense.

Perhaps it even makes sense when you have a number of values you’d like to set:

For simple use cases, that isn’t too bad. But when you start having conditionals where you’re swapping sets of values, where you’re toggling stuff on and off, and interspersing those needs… it gets hairy:

When using a string-interpolation-based template like Helm each of those becomes something like this, at best:

It gets worse with complexity, such as a nested conditional like this:

These become very unwieldy to reason about and manage. Really, at that point someone should have stopped and asked “what am I doing here?” If not, then certainly when you find yourself typing “indent 2” you should be asking some questions. We’re dealing with well-defined, structured data formats after all. Hell, often they have an actual schema. Why would you possibly treat something with a defined, trivially manipulatable structure as an unstructured string? If you opened code in any language and saw someone building a dictionary or an array via string interpolation, you would almost certainly ask why they were doing that.
The Kubernetes team explained that they chose YAML because it is reasonably easily readable and editable by both humans and machines. They didn’t mean for humans and machines to just treat it as unstructured character streams. It is easy to see why tools have evolved and opted to use string-interpolated templates though. For simple cases, it makes sense enough — it’s not that bad to set a value via templating. Even when passing in multiple values, it’s probably still ok. But, once you’re at control-flow constructs like conditionals, this is not the right solution.
Templates contain business logic
With Helm, organizations often implement what I call a “god chart” or “one chart to rule them all” in order to provide developers with a common application deployment model. It usually starts simple but then evolves organically over time into a tangled ball of yarn that’s difficult to maintain and nearly impossible to test. The road to hell is paved with good intentions.
The situation quickly gets really nasty because there are actually multiple distinct things happening. One common need is to swap out a lot of “static” stuff (values, structure, or both). This can cause a lot of noise within a string-interpolated template, but you for sure don’t want to copy/paste your template because it also contains your business logic.
Take a short pause and say this out loud: my string-interpolated template contains my business logic.
You layer in value injection throughout your data structure, that you’re treating like a stream of characters, and now we need to add more logic, like conditionals, in order to handle toggling values on or off or deciding to include blocks. If we include them, we need to inject their values as well. Now we have a real situation. We have a lot of logic, nestled inside a string — a string that is actually a well-defined data structure.
Interpolation vs. Overlay
Koreo lets you approach these needs with different, purpose-built constructs. First, to swap big-block structural things or static values, you can swap the entire “base”:

Using a tool like kpt, you can keep those in sync. If you don’t want kpt, then just copy/paste or use whatever diff tool you like. These are just the static structures and static or default values.
Static values? That’s limiting. If I just had static values, I’d use Kustomize — and you should. It’s great for this case. It is the inspiration for Koreo’s approach to overlays.
Remember, we’ve got structured data here. To address value or structural updates based on computed logic, you can apply overlays. Koreo overlays are really just a set of atomic updates which are applied (using real data structures) that behave how you’d do this in code:
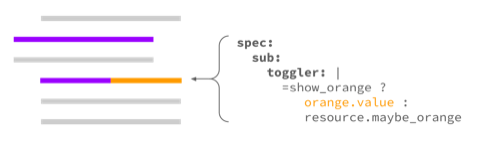
The overlay lets you specify an atomic set of updates to be applied. No JSON path stuff needed. You write the overlay more or less as you would in code, using a simple but powerful expression language to specify your logic. Koreo evaluates the expressions, converts them into an update, and applies them. That example above is just like setting a dictionary value. It converts to something similar to this:
resource.spec.sub.toggler = "orange"You specify the path you’d like updated, provide the value expression, and then the value will be updated. You can update multiple fields and sub-structures within a single overlay. You can even do things like map over values from configuration or the base resource specification in order to filter or change the values within the list or map.
In fact, that is what Koreo does. It takes your overlay spec and builds an “update index” which tells Koreo the specific properties in your data structure you want updated. Then it evaluates your expressions and uses the update index to set the computed values. In practice, it looks just like you’d write this in “real” code.
This approach gives a really clean model that leverages the fact we’re dealing with well-defined data structures. Having a big, nasty overlay is better than the logic being within a string-interpolated template, but it isn’t a lot better. Instead, Koreo lets you have sane logic and “point” updates because you can (optionally) layer the overlays themselves. What’s even better with this model is that they’re ideally small and they are always testable. They’re always testable because they are pure functions and Koreo contains a first-class testing framework that is built into the language itself. You can test the entire set of overlays to ensure the resource is correct:

But you can actually test each overlay in isolation via the same testing framework. That means rather than an insane huge template that you’re trying to test, you write something like unit tests for the data structure updates. That makes it so that you can ensure your overlays individually function correctly and that they update the correct fields with the correct values. Then you can write a few tests to ensure the correct overlays are applied and that they work together correctly. It is like some form of black magic, and no sacrifices were even required — just treating structured data like structured data.
This layered approach to resource materialization provides a means for “factoring” different configuration concerns into reusable, testable building blocks. For instance, the security team wants to ensure specific encryption configuration is enabled, the compliance team wants to ensure data-retention policies are set, and the SRE team wants to ensure data replication is configured appropriately.

Treating configuration as code
Of course, string templating isn’t the only approach that has been used to manage Kubernetes configurations. Configuration languages like Jsonnet, Cue, and Dhall attempt to solve some of these challenges by treating configuration as structured data rather than text. These languages introduce programming constructs like variables, conditionals, and functions while maintaining a declarative model. However, they often introduce their own complexity. Jsonnet, for example, provides a powerful way to generate JSON/YAML but can quickly become difficult to debug due to its evaluation model. Cue enforces strong validation but requires a different way of thinking about constraints and configurations.
Each of these tools attempts to move beyond naive string interpolation and offer a step in the right direction, but they still operate largely as external DSLs rather than being deeply integrated into the Kubernetes Resource Model. There’s power in being able to leverage a “real” programming language for configuration, but sometimes being overly expressive is a drawback. What we want is a nice balance of expressiveness that is still deterministic.
Koreo strikes that balance by embedding structured configuration directly into Kubernetes in conjunction with resource orchestration. Instead of treating configuration as text or an external DSL, Koreo provides a native, programmatic approach that integrates seamlessly with the Kubernetes Resource Model. This structured foundation enables features that go beyond simple templating — such as its built-in test framework, which is designed for testing async, event-driven control loops without requiring a tremendous amount of boilerplate or test harness setup. It makes modeling complex scenarios easy and supports validating happy paths, error handling, and template rendering.
Additionally, the Koreo language server integrates with your IDE, providing real-time feedback, autocomplete, and introspection. This makes creating and manipulating data structures feel like working in a real programming language rather than twiddling YAML or editing string-interpolated templates.
This represents a fundamental shift in how we approach Kubernetes configuration management and structured data orchestration. Koreo simplifies the management of complex configurations. It achieves this by moving away from string-interpolated templates and adopting a structured, programmatic approach that’s native to Kubernetes. Its overlay system allows for precise, testable updates, eliminating the fragility and complexity of traditional templating. With a built-in testing framework and IDE integration, Koreo makes working with Kubernetes configuration feel more like actual programming. Ultimately, it provides a platform engineering toolkit that allows you to build powerful abstractions on top of Kubernetes.
Configuration management + resource orchestration
But configuration is only one part of the story. Managing infrastructure effectively requires not only better configuration management, but also a way to orchestrate resources and reconcile changes over time. This is where Koreo extends beyond just managing structured data — it provides a controller-driven model that ensures configuration changes are continuously reconciled, just like Kubernetes itself does for workloads.
Rather than treating Kubernetes resources as static manifests to be generated and applied, Koreo embraces a dynamic, event-driven model where configurations are continuously managed and updated based on changing conditions. This allows us to do more than simply treat configuration as structured data. It enables a truly controller-driven approach to infrastructure management by providing a way to program and compose control loops.

