Implementing Event-Driven Data Architectures in Konfig
Welcome, data engineers, backend developers, and cloud technologists! As the title says, we’re diving into the world of event-driven systems, and we’re doing it using Konfig on Google Cloud Platform (GCP). If you are not familiar, Konfig is an opinionated platform engineering tool to make your life easier when setting up systems in the cloud. It bundles in all of the best practices so you don’t need to spend time on undifferentiated work trying to correctly tie resources together, set up flaky CI/CD pipelines or worry about state drift. Without further ado let’s get into building the system!
The Architecture
The system we will be building is designed for efficiency, allowing it to process data rapidly and seamlessly. Here’s how the flow works:
- Data makes its entrance, dropping into a Google Cloud Storage (GCS) bucket.
- A Storage Notification, our event trigger mechanism, ushers the data towards a Pub/Sub topic.
- Pub/Sub then triggers a Cloud Run service to begin processing the data.
- The Cloud Run service transforms the data and writes it to Firestore.
- A second Pub/Sub topic, triggered by the Firestore write, will initiate an analytics-focused Cloud Run service.
- Finally, the data is stored in BigQuery, where it’s prepared for comprehensive analytics.
We built this system to showcase how Konfig workloads can work together harmoniously. Each workload naturally decouples the system, creating a structure that aligns well with distributed domain driven design. For the data enthusiasts out there, this approach is similar to data mesh architecture. The benefits? Improved scalability, easier maintenance, and greater team autonomy.
Building the System
Before we dive into the code, let’s discuss the anatomy of a workload in Konfig. Workloads are declaratively defined using YAML. This file sits alongside the application source code which lives in a Workload repository. This setup ensures you get best practice SDLC processes for both your workloads and the resources defined within them.
A workload specifies three key elements:
- A runtime engine e.g. (Cloud Run, Kubernetes)
- A resources list specifying the infrastructure
- Triggers for implementing event or cron-based invocations of the workload
For a deeper dive into workloads and their components, check out our comprehensive documentation for a complete guide to building workloads.
Now we are primed to dive into the code!
1. Cloud Run Service Runtime
First, we’ll set the stage with our initial Cloud Run runtime:
This service is the backbone of our operation, handling the business and transform logic. It’s designed to execute when messages hit our Pub/Sub subscription, which we will define next.
Here’s the flow:
- It spins up a server to handle POST requests from the Pub/Sub subscription.
- Writes a record to the Firestore DB.
- Writes to a Pub/Sub topic upon successfully writing to this DB.
This setup gives us a flexible, event-driven architecture that’s ready to scale.
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: konfig-data-loader
spec:
runtime:
apiVersion: run.cnrm.cloud.google.com/v1beta1
kind: RunService
metadata:
name: konfig-data-loader
spec:
template:
containers:
- image: konfig-data-loader
env:
- name: FIRESTORE_COLLECTION
value: loader-collection2. Pub/Sub trigger
Next, we define our Pub/Sub trigger for the above runtime.
triggers:
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubSubscription
metadata:
name: konfig-data-loader-subscription
spec:
ackDeadlineSeconds: 15
messageRetentionDuration: 600s
retainAckedMessages: false
topicRef:
name: konfig-data-loader-topicThis trigger configures a subscription on a Pub/Sub topic which will:
- Receive messages from a GCS bucket
- Invoke the Cloud Run service.
Key Points:
- This Pub/Sub subscription is automatically set to a push configuration, simplifying our handler service definition.
- Konfig intelligently sets up custom IAM Service Accounts with the appropriate roles for each workload.
- Once deployed, you can verify everything through the Konfig UI and the GCP console.
Notes: Konfig leverages Google’s Config Connector to manage your resources. This pattern was adopted for simplicity in resource definition.
3. Resources
Now, let’s dive into the list of services needed to complete this workload. We’ll break it down into smaller, digestible chunks.
Custom Trigger with GCS and StorageNotification
Our first set of resources showcases Konfig’s flexibility:
- GCS Bucket: The storage location for our objects.
- StorageNotification: This activates when an object is uploaded to our GCS Bucket.
- IAM Policy Member: Ensures proper permissions for the StorageNotification.
This setup demonstrates a key strength of Konfig: while we can use pre-defined triggers (like the Pub/Sub topic we saw earlier), we’re not limited to them. You can customize your workload to fit your specific needs.
Extending Konfig with Resource Templates
Konfig allows you to go beyond its native support through resource templates. Here’s how it works:
- In this case, we’re using StorageNotification, which does not natively have a default template in Konfig.
- Create a default resource template: Our custom trigger uses a StorageNotification object to write a message to the Pub/Sub topic (defined earlier as our trigger) when an object is uploaded to the GCS Bucket.
Here is the default resource template we use for the Storage Notification:
apiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageNotification
metadata:
name: default
namespace: konfig-templates
spec:
bucketRef:
name: default
namespace: konfig-templates
payloadFormat: JSON_API_V1
topicRef:
name: defeault
namespace: konfig-templates
eventTypes:
- "OBJECT_FINALIZE"
- "OBJECT_METADATA_UPDATE"This approach gives you the power to tailor Konfig to your unique requirements, combining the ease of pre-built components with the flexibility of custom solutions.
resources:
- apiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageBucket
metadata:
name: konfig-data-loader-data-source-landing
spec:
lifecycleRule:
- action:
type: Delete
condition:
age: 7
withState: ANY
- apiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageNotification
metadata:
name: konfig-data-loader-storage-notification
spec:
bucketRef:
name: konfig-data-loader-bucket
namespace: my-sweet-namespace
topicRef:
name: konfig-data-loader-topic
namespace: my-sweet-namespace
- apiVersion: iam.cnrm.cloud.google.com/v1beta1
kind: IAMPolicyMember
metadata:
name: konfig-data-loader-storage-notification
namespace: my-sweet-namespace
spec:
member: serviceAccount:service-project-number@gs-project-accounts.iam.gserviceaccount.com
role: roles/pubsub.publisher
resourceRef:
kind: PubSubTopic
name: konfig-data-loader-topicThis second set of resources completes our workload setup with three key components:
- Pub/Sub topic: This is the topic we subscribed to in our trigger definition.
- Firestore database: For data storage and retrieval.
- Output Pub/Sub topic: This topic receives a message upon successful writes to the Firestore DB.
Key Points:
- These resources are natively supported by Konfig.
- Konfig automatically sets up the appropriate service accounts and roles set up for our Cloud Run service to interact with these resources.
- With this infrastructure in place, we can now focus solely on writing the code we need to give the system life.
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubTopic
metadata:
name: konfig-data-loader-topic
spec:
messageRetentionDuration: 600s
- apiVersion: gcp.konfig.realkinetic.com/v1alpha8
kind: FirestoreDatabase
metadata:
name: konfig-data-loader
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubTopic
metadata:
name: konfig-data-loader-firestore-topic
spec:
messageRetentionDuration: 600s4. Analytics Workload
Now, let’s build our analytics workload. This is where Konfig’s elegance truly shines. We will seamlessly integrate this analytics workload with the one we just created, without the hassle of manually configuring IAM pieces.
This pattern should look familiar now:
- Pub/Sub trigger: We’ll reference the `konfig-data-loader-firestore-topic` defined in the previous workload.
- Cloud Run service: We’ll set up the runtime with the necessary environment variables to properly configure this service.
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: konfig-analytics-workload
spec:
triggers:
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubSubscription
metadata:
name: firestore-data-load-subscription
spec:
ackDeadlineSeconds: 10
retainAckedMessages: false
topicRef:
name: konfig-data-loader-firestore-topic
runtime:
apiVersion: run.cnrm.cloud.google.com/v1beta1
kind: RunService
metadata:
name: WORKLOAD_NAME
spec:
template:
containers:
- env:
- name: GCP_PUBSUB_SUB_ID
value: data-transform-subscription
- name: GCP_FIRESTORE_COLLECTION_NAME
value: loader-collection
- name: GCP_BIGQUERY_TABLE_NAME
value: konfig_demo_dt
image: konfig-analytics-workload5. Analytics Workload Resources
Let’s take a closer look at these resources to showcase how Konfig handles cross-workload resource sharing.
New and Familiar Resources
- BigQuery Dataset (New): This will house the analytics tables we need to get those valuable insights.
- Firestore DB (Familiar): Reused from the previous workload.
- Pub/Sub Topic (Familiar): Also reused from the previous workload.
Key Feature: Resource Annotations
Notice the annotations on the Pub/Sub topic and Firestore DB. These annotations specify this workload as a user of these resources. This feature brings two significant benefits:
- Resource Persistence: If our first workload gets deleted for any reason, these shared resources will remain intact, ensuring no disruption to this analytics workload.
- Team Autonomy: Our analytics team can work on their own workload independently, outside of their data sources’ domain (in this case, our first workload).
resources:
- apiVersion: bigquery.cnrm.cloud.google.com/v1beta1
kind: BigQueryDataset
metadata:
name: bigquery
- apiVersion: gcp.konfig.realkinetic.com/v1alpha8
kind: FirestoreDatabase
metadata:
name: konfig-data-loader
annotations:
konfig.realkinetic.com/ownership_role: user
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubTopic
metadata:
name: konfig-data-loader-firestore-topic
annotations:
konfig.realkinetic.com/ownership_role: userImplications for Team Structure and Maintainability
This setup exemplifies what we discussed earlier about:
- Team Autonomy: Different teams can work on separate workloads while sharing resources.
- Maintainability: Resources are preserved even if originating workloads are removed, enhancing system resilience.
This approach allows for a more flexible and robust architecture, where teams can operate independently while still benefiting from shared resources.
Deploying the System
Natively, Konfig integrates with GitLab CI/CD, meaning when you create a new workload you automatically get a repository set up for you and a CI/CD pipeline tailored to your workload. This makes CI/CD a non-issue, so much so we forget to write about it sometimes! It is easy to forget that this piece is where some teams find themselves spending countless hours getting a CI/CD pipeline setup.
Not to mention you get a dev, stage, and production environment out of the box so you decide when you go to production while giving yourself a nice sandbox to work in until you are ready. Konfig facilitates deployment-driven development, where you ship your work on the first commit. This approach, combined with segregated environments, allows teams to:
- Test in production-like environments from day one
- Iterate quickly and safely in lower environments
- Promote code through stages with confidence
- Maintain clear separation between development, staging, and production workloads
By embracing this model, teams can focus on delivering value rather than wrestling with deployment complexities.
Once our pipeline is complete for both of our workloads we can head to the Konfig UI and watch all of our resources start to spin up in GCP. When our resources are completely provisioned we can take this system for a spin!
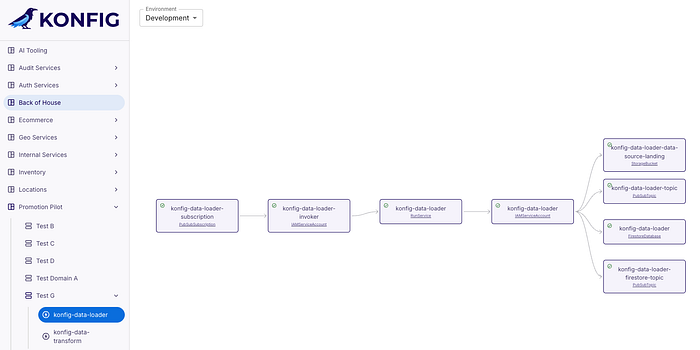
Testing the System
Let’s navigate to the console to ensure everything is functioning as expected. First, we’ll check the GCP Bucket to confirm its existence, and then I’ll upload a sample message to trigger the system.
As we head over to the Cloud Run page we see our services are online and looking good!
A wonderful thing about Cloud Run is we can good logging out of the box. I went ahead and sprinkled in some logs to make sure the services we triggered properly. Here we go, look at those beautiful logs!
The message is alive and well in Firestore!
We can also see our analytics record in BigQuery!
Wrap-Up
I know we covered a lot in this article. We will be going into more depth on these different concepts in the coming weeks!
The goal of this article is to demonstrate how Konfig empowers you to simplify the creation of event-driven systems, enabling faster development and greater team autonomy. This isn’t just because I’ve been involved in building it; I genuinely believe it will make the day-to-day of software, data, and infrastructure engineers suck less. Look, the reality is that companies are finding it harder and harder to justify bringing on more individual contributors. This means we as the builders now have to know every part of the stack. I am not talking about front-end vs. backend. I mean every step it takes to deliver your work to production, meaning CI/CD, managing source control in a sane way, building segregated deploy environments, knowing container management, debugging Kubernetes, IaC. This is what we have set out to solve with Konfig. Giving the engineer their sanity back by building out all of the undifferentiated work for you. You will be able to deliver value right away. Good news for you: we are accepting early adopters right now. If anything in this post interests you, or you have questions on how Konfig can help you or your organization hit us up!

