Links: 4/9
Business / Government / Management / News
What this Silicon Valley VC learned on the ‘Rust Belt Safari’
A few weeks ago, two members of Congress — Tim Ryan, D-Ohio, and Ro Khanna, D-Calif., — pulled a reverse “Mr. Smith Goes to Washington” and sardined a dozen VCs into a tour bus. Our fund helped pull the trip together, visiting with leaders in “comeback cities” — Youngstown, Akron, Flint, Detroit and South Bend.
We were trying to figure out how we, the “rapacious vultures,” might invest more money in these heartland cities. We want to be part of making our country stronger, and to find investment opportunities outside our little corners.
We thought we’d be seeking hidden gems ; what we really found was fertile soil. Fertile for new startups, yes, and also for second offices for later-stage companies unable to squeeze one more standing desk into their SoMa open offices. For us investors, these comeback cities offer a chance to scale our “boutique” practice of investing in technology. There are plenty of ways for tech to play here.
- Uh … no shit.
- I shouldn’t be an ass about this as at least some folks in the valley are finally waking up and are attempting to better expand and actually focus on the needs of “not rich people in the valley”.
Google veteran Jeff Dean takes over as company’s AI chief
Programmer Jeff Dean was one of Google’s earliest employees, and he is credited with helping to create some of the fundamental technologies that powered the tech giant’s rise in the early 2000s. Now, he’s been put in charge of Google’s future, taking over as head of the company’s artificial intelligence unit.
The move is part of a reshuffle at Google, first reported by The Information and confirmed by CNBC, that’s seems designed to push AI into more of the company’s products. Previously, AI product development was overseen along with search by senior vice president of engineering, John Giannandrea. Now, this role is being split into two, with Dean taking over AI, and Ben Gomes leading the development of search.
- I would have thought this was already how they were set up.
- I do my best to not idolize anybody (or anything) but in our, industry Jeff is certainly worthy of admiration. He’s had a significant impact on much of the current infrastructure in modern tech.
- And this makes way more sense with: https://www.nytimes.com/2018/04/03/business/apple-hires-googles-ai-chief.html
The death of the newsfeed
I was reminded of this recently by the fact that, according to Facebook, its average user is eligible to see at least 1,500 items per day in their newsfeed. Rather like the wedding with 200 people, this seems absurd. But then, it turns out, that over the course of a few years you do ‘friend’ 200 or 300 people. And if you’ve friended 300 people, and each of them post a couple of pictures, tap like on a few news stories or comment a couple of times, then, by the inexorable law of multiplication, yes, you will have something over a thousand new items in your feed every single day.
This is the combination of two factors — Dunbar’s number (a rule of thumb that implies that you probably do know several hundred people well enough to friend them on Facebook) and ‘Zuckerberg’s law’ (the supposed tendency to share more and more on social media over time). Combine these two and you get overload.
Pushing a little further, it seems to me that Zuckerberg’s law, such as it is, is really an observation about the models for following people that social media platforms have evolved, in which sharing something onto your own feed is not the same as sending it to any particular person. You would not send 10 pictures of your child or dog to everyone in your address book very often, if ever, and most people (under 50) would not send every funny or enraging news article they see to everyone in their address book either, but the asymmetric feed makes posting at that kind of frequency normal instead of rude. Since you’re posting it to ‘your’ feed instead of sending it explicitly to someone, it’s OK to post lots and to post less important things. That, in turn, takes us to the tragedy of the commons — we’re ‘supposed’ to post stuff, but by posting stuff, we overload each other’s feeds. Facebook’s Growth team was too good at its job.
- Pretty interesting read. And hard to deny the theory.
- Specifically this tweet:
- This may all be solvable but in the meantime, the cycle continues. I’m currently back in the manually curate cycle with some algorithmic influence.
Apps of a Feather …Stick Together
The Problem
After June 19th, 2018, “streaming services” at Twitter will be removed. This means two things for third-party apps:
1. Push notifications will no longer arrive
2. Timelines won’t refresh automatically
If you use an app like Talon, Tweetbot, Tweetings, or Twitterrific, there is no way for its developer to fix these issues.
We are incredibly eager to update our apps. However, despite many requests for clarification and guidance, Twitter has not provided a way for us to recreate the lost functionality. We’ve been waiting for more than a year.
- Twitter continuing to hate their users. It’s amazing how abusive these companies are to their own users as a reaction to their own failures. People use alternative apps because you’re not providing something they value. So instead of providing that value or a way for others to provide that value, you decide to force your users into a worse experience.
Quick Hits:
- The cost of predictability — shipping great products when we’re either always late or wrong.
- Satya Nadella email to employees: Embracing our future: Intelligent Cloud and Intelligent Edge
- Apple Plans to Use Its Own Chips in Macs From 2020, Replacing Intel
- Before you MVP
- AirPods and the Three Stages of Apple Criticism
- Why is Agile the most overused word in software business?
- Facebook: ‘Malicious actors’ used its tools to discover identities and collect data on a massive global scale
Systems / Infrastructure / Cloud
No, Panera Bread Doesn’t Take Security Seriously
tl;dr: In August 2017, I reported a vulnerability to Panera Bread that allowed the full name, home address, email address, food/dietary preferences, username, phone number, birthday and last four digits of a saved credit card to be accessed in bulk for any user that had ever signed up for an account. This includes my own personal data! Despite an explicit acknowledgement of the issue and a promise to fix it, Panera Bread sat on the vulnerability and, as far as I can tell, did nothing about it for eight months. When Brian Krebs publicly broke the news, other news outlets emphasized the usual “We take your security very seriously, security is a top priority for us” prepared statement from Panera Bread. Worse still, the vulnerability was not fixed at all — which means the company either misrepresented its actual security posture to the media to save face or was not competent enough to determine this fact for themselves. This post establishes a canonical timeline so subsequent reporting doesn’t get confused.
- Another day, another ignored vulnerability by a large company. I’m sure this time they’ll finally be held accountable. (SPOILER: They won’t.)
Announcing 1.1.1.1: the fastest, privacy-first consumer DNS service
Cloudflare’s mission is to help build a better Internet. We’re excited today to take another step toward that mission with the launch of 1.1.1.1 — the Internet’s fastest, privacy-first consumer DNS service. This post will talk a little about what that is and a lot about why we decided to do it. (If you’re interested in the technical details on how we built the service, check out Ólafur Guðmundsson’s accompanying post.)
- I might need to give this a look (I’ve been having some issues with having Google set).
- Yep. I for sure need to give this a look:
- CloudFlare was the fastest DNS for 72% of all the locations. It had an amazing low average of 4.98 ms across the globe.
Quick Hits:
- How the end-to-end back-pressure mechanism inside Wallaroo works
- Queues Don’t Fix Overload (Old but gold).
- Netflix FlameScope
- AWS Secrets Manager — Store, Distribute, and Rotate Credentials Securely
- AWS Config Rules Update — Aggregate Compliance Data Across Accounts & Regions
- Kubernetes Security Guide, Chapter 1: Kubernetes RBAC and TLS certificates
- Computer system transcribes words users “speak silently”
- GitLab gets a native integration with Google’s Kubernetes Engine
- DevOps as the Art and Science of Deliberate Practice
- Building Check-In Queuing & Appointment Scheduling for In-Person Support at Uber
- It takes more than a Circuit Breaker to create a resilient application
Math / Science / Behavior / Economics
Smart Guy Productivity Pitfalls
Productivity is one of my pet topics, because it’s always dogged me a bit, especially early in my career. I’d pull long days and nights and then realize I only actually worked (as in, typing in code, debugging stuff, and thinking about problems and their solutions) maybe 20% of the time. Upon talking to coworkers, this seemed to be normal, a part of the expected friction costs incurred working in an office environment. Meetings, shooting the shit with coworkers, lunch, email, and, er, stuff.
Eventually working around high-productivity professionals like John Carmack made me realize that if you want to excel, then you have to work hard and focus the whole time.
I remember Carmack talking about productivity measurement. While working he would play a CD, and if he was not being productive, he’d pause the CD player. This meant any time someone came into his office to ask him a question or he checked email he’d pause the CD player. He’d then measure his output for the day by how many times he played the CD (or something like that — maybe it was how far he got down into his CD stack). I distinctly remember him saying “So if I get up to go to the bathroom, I pause the player”
- I love any Carmack stories. Masters of Doom is one of my favorite books.
- There are also some really good tips and advice in here.
The Evolution of Trust
- I came across this last year and loved it. And I just again stumbled across it on Twitter. Worth the share. Visuals and games (interaction) are so great for learning.
Blockchain / Crypto
Disaggregation Theory: where does value accrue in the decentralized web?
In Internet 3.0 and the demise of state aggregators, I suggested that because blockchains can capture state (user data) at the protocol level, state aggregators like Facebook would lose their moat, creating an opportunity for decentralized competitors. If we define Internet 2.0 as the widespread disruption caused by aggregation of state, then Internet 3.0 will be defined by the widespread disruption caused by moving state aggregation to the protocol level.
In the conversations I’ve had following my post, I was reminded of Ben Thompson’s 2015 post on Aggregation Theory: “A framework to understand the impact of the internet on nearly all industries.” Aggregation Theory contends that as a result of the internet, serving users went from material marginal cost to zero marginal cost. Pre-internet, value was captured in owning distribution and integrating backwards into supply. Post-internet, value was captured in owning distribution and integrating forward into discovery and user data.
- An interesting article.
- I’m pessimistic that users will ever choose security/privacy over UX without force:
Users will have to make a choice between the superior UX of today’s internet companies and the superior privacy and data sovereignty of decentralized internet companies. Long term, this gap will close as users can offer more data to discovery engines and UX handicaps are removed. But there’s still the probable possibility that decentralized apps will never provide the same kinds of magical (and sometimes creepy) experiences as today’s internet companies.
- If blockchain wants to become the new internet they will need to figure UX out. It will need to be very close to the same level of quality as current standards. Yes, you’ll get early adopters (geeks like us) but that’s not enough. The average user has never jumped on IRC. They didn’t do IRC until it was an easy and pleasant user experience (yahoo, messenger, fbook chat, etc). I do think this is a solvable problem and there areenough potential and interest that I believe it will be resolved.
AI / Machine Learning / Data Science

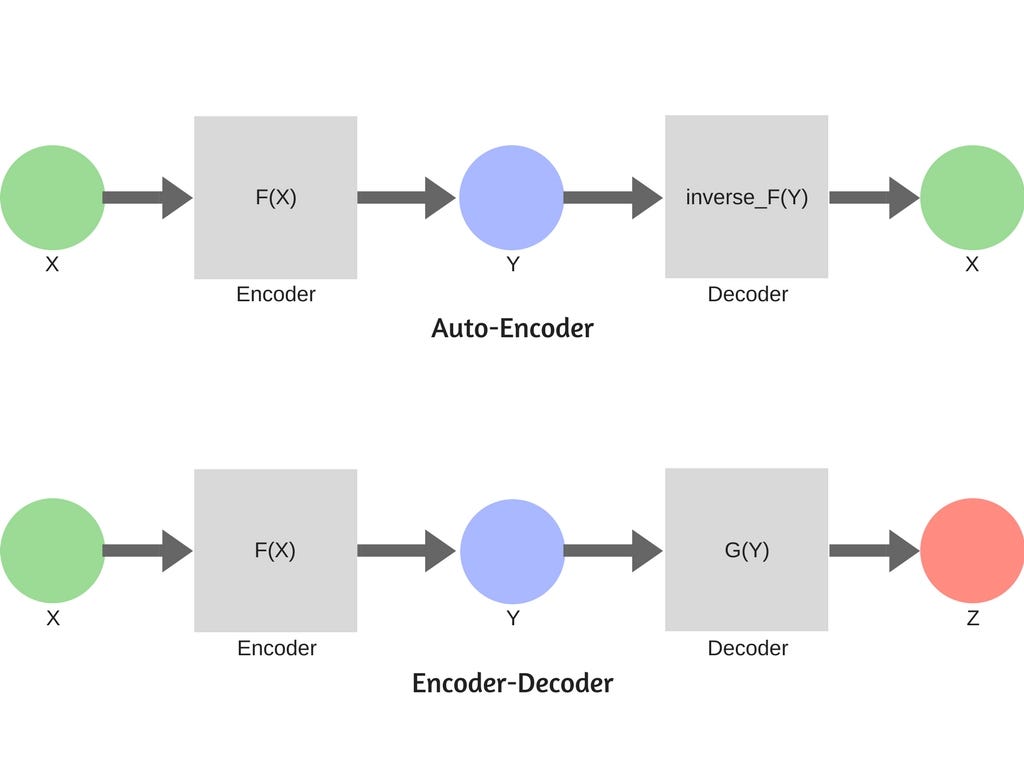
Information Theory of Neural Networks
Opening the Black Box …. Somewhat
“Information: the negative reciprocal value of probability.” — Claude Shannon
Aim of this blog is not to understand the underlying mathematical concepts behind Neural Network but to visualise Neural Networks in terms of information manipulation
- This is pretty cool. I love information theory. And I love new ways to present complex concepts. Of which both information theory and neural networks can be.
If you’re looking for help with your architecture or development organization feel free to reach out: realkinetic.com @real_kinetic
You can follow me directly @lyddonb

{kind=link}